Unlocking Entertainment Intelligence with Knowledge Graph

<p>Author: <a href="https://www.linkedin.com/in/himanshu92/">Himanshu Singh</a></p><p>Entertainment today is a sprawling universe of interconnected stories, characters, creators, and companies. With d...
Author: Himanshu Singh
Entertainment today is a sprawling universe of interconnected stories, characters, creators, and companies. With data flowing from millions of titles, talent profiles, books, and more, traditional approaches to data management and analytics often fall short. Disconnected silos, inflexible schemas, and slow onboarding processes limit the ability to extract meaningful insights from rich entertainment data.
Our Entertainment Knowledge Graph — an ontology-driven architecture enables Netflix to unify disparate entertainment datasets into a cohesive data ecosystem. This transformative approach empowers analytics, machine learning, and strategic decision-making with unprecedented agility and clarity.
Why a Knowledge Graph?
Knowledge graphs fundamentally change how data is structured, accessed, and interpreted by representing entities (such as films, actors, books, and characters) and their relationships as first-class concepts.
Here’s why this matters for entertainment intelligence:
Semantic Connectivity
Traditional databases isolate data in separate tables or systems. Knowledge graphs, on the other hand, store entities and relationships in interconnected structures, enabling powerful semantic queries. Questions like “Which actors have worked frequently with this director?” or “Which novels have inspired successful films?” become trivial. Rich semantic connectivity allows us to rapidly derive insights without cumbersome joins or manual lookups.
Conceptual Consistency
Using a shared ontology as the backbone ensures standardized vocabulary across engineering systems. Multiple components across multiple ETL pipelines reference consistent definitions, reducing misinterpretations and duplication and promoting collaboration. Standardized definitions of entities and relationships ensure clarity and uniformity in analyses and reports.
Agile Evolution
The entertainment landscape evolves rapidly, with new types of content, media formats, and entity metadata emerging frequently. Our knowledge graph architecture is inherently flexible, enabling rapid integration of new entity types or relationships. Rather than restructuring databases or redefining APIs, we simply extend our ontology and incorporate new data seamlessly, keeping pace with dynamic business needs.
How We Use Knowledge Graph at Netflix
At Netflix, the Entertainment Knowledge Graph is leveraged across various domains, enabling applications that demand contextual understanding, semantic linkages, and cross-domain intelligence:
- Content Evaluation: Contextual metadata in the graph enables comparative analysis and the generation of insights across similar titles based on narratives, themes, or production elements.
- Market Intelligence: The graph captures relationships between companies, creators, genres, and regional trends, aiding in the analysis of emerging talent or popular genres.
- Talent Insights: Understands and surfaces multifaceted attributes of talent — roles, genres worked in, affiliations — facilitating better understanding of talent market.
- Machine Learning Applications: Feeds entity embeddings and structured relationships into downstream models for personalization, search, demand predictions, and recommendations.
Architectural Pillars of the Knowledge Graph
Our Entertainment Knowledge Graph architecture is built on three key pillars: ontology-driven data modeling, RDF-based graph structures, and unified access and integration capabilities.
1. Ontology-Driven Data Modeling
At the core of the knowledge graph is an ontology — essentially a comprehensive blueprint defining how data entities, attributes, and relationships interrelate. An ontology-driven data modeling enables:
- Rapid Onboarding — New entity types (such as emerging entertainment formats or attributes like streaming analytics) are quickly defined and integrated into the existing ontology, significantly reducing onboarding time from weeks to days.
- Unified Schema — All our data consumers reference the same ontology definitions, ensuring consistent and reliable interpretation across diverse use cases — from predictive modeling to strategic planning.
- Easy Adaptation — Changes in business logic or new data requirements can be effortlessly accommodated by updating the ontology without disrupting downstream processes.
2. RDF Triples & Graph Storage
RDF (Resource Description Framework) triples — comprising a subject, predicate, and object — form the foundational data storage mechanism in the knowledge graph ETL pipelines, providing significant benefits:
- Unified Data Store: A single triple store encapsulates all entities, relationships, and metadata. This unified structure eliminates the need for joins across disparate tables which may be hard to discover and interpret.
- Rich Data Lineage Tracking: Each RDF triple contains detailed metadata, including provenance (source information), timestamps, and confidence scores. We can effortlessly trace the origin of data points, understand their evolution, and assess quality.
- Embedded Confidence Scoring: Every triple can carry confidence metadata, indicating data reliability and source quality. Analysts and ML engineers can easily prioritize high-confidence data for critical decisions.
3. Unified Data Access and Source Integration
By structuring data in a knowledge graph, we enable unified yet flexible access patterns for various business needs and streamline the integration of new data sources:
- Flexible Data Interpretation: The graph can be queried differently based on the analytic context — such as retrieving data at granular levels (individual episodes of a show) or aggregated superclass levels (such as all content types).
- Easy Source Integration: New external or internal data sources are integrated rapidly by mapping them into our existing ontology and graph structure. This significantly reduces the overhead and complexity typically associated with onboarding new datasets.
- Customized Views: Different teams or use cases may require distinct views of the same underlying data. With our triple store and ontology, we can easily generate custom views or subsets of the data tailored specifically to each stakeholder’s needs, all derived from the single source of truth.
Data Ingestion Flow
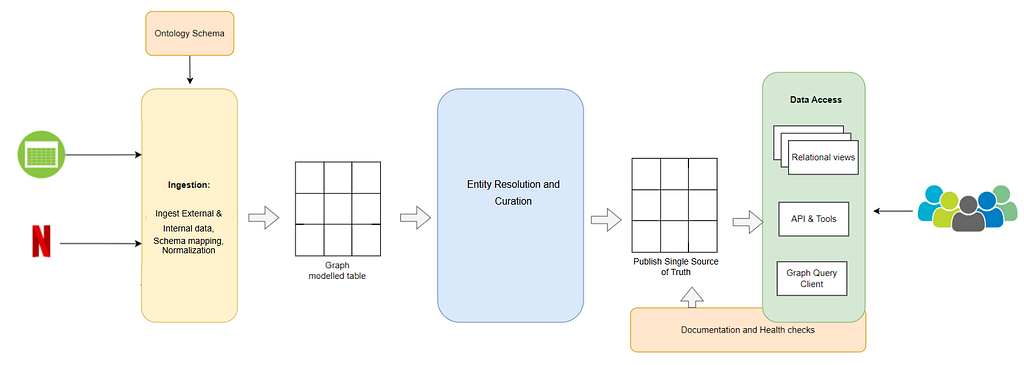
Building and maintaining the Entertainment Knowledge Graph involves a multi-phase ingestion pipeline, converting raw external and internal data into structured graph-based knowledge:
- Ingestion: We ingest data from a wide array of sources, including the open web, structured licensed datasets, and proprietary Netflix metadata. This raw data provides the foundational building blocks for the knowledge graph.
- Schema Mapping: The ingested data is mapped to our internal ontology. This mapping aligns diverse terminologies and formats into a standardized schema, ensuring consistency across all data ingested into the graph.
- Normalization: Once mapped, the data undergoes normalization to ensure uniformity in formats, units, naming conventions, and relationships. This step eliminates discrepancies and prepares the data for integration.
- Match and Merge: Entities from different sources are matched and merged to avoid duplication. For example, different representations of the same film or actor across multiple datasets are reconciled into a single entity in the graph.
- Curate: The graph is further enriched through curation via automated signals. Derived data, additional relationships, and corrections are added at this stage to improve quality and completeness.
- Publish: Finally, the curated knowledge graph is published to downstream consumers. This includes making it accessible via APIs, tools, relational views, and query clients — enabling self-serve and integrated analytics across the organization.
Unified Ecosystem Across Teams and Functions
With the Entertainment Knowledge Graph, diverse teams within Netflix gain streamlined access to a unified entertainment knowledge base:
- Data Science & Machine Learning: Utilize context-rich embeddings derived from the graph’s structure to power recommendation models, predictive analytics, and content valuation algorithms.
- Analytics & Business Intelligence: Leverage unified graph-based views of entertainment data for consistent reporting and trend analysis, enabling clearer insights into audience behaviors and market trends.
- Strategic Planning & Decision-Making: Easily navigate the data to explore complex scenarios about market positioning, talent insights, content performance, and competitor strategies, all enriched by robust lineage tracking and confidence scores.
Challenges
Despite its strengths, using a knowledge graph to unify entertainment data poses significant challenges. One of the biggest challenges is the difficulty of consuming graph data. Users at Netflix, particularly analytical engineers and data scientists, are accustomed to SQL-like environments and relational formats. While we have unified substantial external insights in the knowledge graph, other datasets within Netflix remain in traditional relational formats more suitable for their respective use cases.
This situation creates complexity, as analytical engineers and data scientists often need to combine datasets across different formats. Handling data provided in graph or triple format alongside relational data is challenging and can significantly slow analysis.
To address this, we transform the graph data and generate relational tables. Essentially, we convert our RDF-based data into property graph data structures, materializing these tables and relationships in formats easily consumed by analytical engineers and data scientists. This approach allows seamless integration of graph-based insights with traditional relational data sources, ensuring our users can efficiently leverage unified data.
Future Outlook
Looking forward, the graph is positioned for continued innovation:
- Advanced Inference Capabilities: Future iterations will integrate advanced reasoning techniques to uncover hidden insights, automatically derive new relationships, and enrich existing knowledge.
- Federated Knowledge Access — Extend unified access across both graph-connected datasets and non-modeled sources to further democratize data usage, enhance collaboration, and reduce redundancy.
- Schema Adaptation: Evolving the ontology dynamically and rapidly will ensure even faster responses to emerging business needs, new data types, and analytic challenges.
The Entertainment Knowledge Graph represents a fundamental shift in how Netflix manages, interprets, and leverages entertainment data. By adopting an ontology-driven, RDF-based architecture, Netflix has created a flexible, unified data ecosystem that enables analytics, machine learning, and strategic decision-making.
This is more than just structured data — it’s unlocking deeper entertainment intelligence and insights at scale, equipping Netflix to confidently navigate the dynamic global entertainment landscape.
Credits: Alyx Rossetti, Bao Ngo, Dave Pedowitz, Himanshu Singh, Ian David, Inna Giguere, John Marsland, Karan Gupte, Mariam Joan, Maciej Kazirod, Michael Li, Natali Ruchansky, Rodrigo Setti.