Integrating Netflix’s Foundation Model into Personalization applications

<p>Authors: <a href="https://www.linkedin.com/in/divya-gadde-3ba01551/">Divya Gadde</a>, <a href="https://www.linkedin.com/in/markhsiao/">Ko-Jen Hsiao</a>, <a href="https://www.linkedin.com/in/dhaval-...
Authors: Divya Gadde, Ko-Jen Hsiao, Dhaval Patel and Moumita Bhattacharya
The motivation for building the Netflix Foundation Model for personalization was laid out in this previous blog post. The Netflix homepage is powered by several specialized models and it requires significant time and resources to maintain and continue innovating on these individual models. Therefore, we decided to centralize member preference learning and have one powerful model learned from comprehensive user interaction histories and content data at a large scale and have this model distribute its learnings to other models.
The previous two blog posts(1, 2) focus on the development of the Foundation Model and here we talk about how we integrate the Foundation Model into various applications. We found that there is extensive literature focused on the training and inference of large-scale transformer-based models. However, there remains a significant gap in practical guidance and research on how to effectively and efficiently integrate large models into existing production systems. At Netflix, we experimented with 3 distinct integration approaches — embeddings, subgraph and fine-tuning. The motivation for trying different approaches stems from varying application needs. Specifically, different teams have different latency requirements, tech stack constraints and different appetites for leveraging the full power of a large foundation model.
In this blog, we go over the 3 approaches we experimented with and which are now used in production for different use cases. Each integration approach has its own set of motivations, tradeoffs, complexities and learnings. The following sections go into the details of each of these integration approaches.
Embeddings from Foundation model
Transformer style foundation models naturally lend themselves to generating comprehensive user profile and item representations. Our approach for generating embeddings includes getting the hidden state of the last user event as the profile embedding and weights from the item tower as item embeddings.
Netflix has an elaborate set up for refreshing the embeddings every day. First, the Foundation Model is pre-trained from scratch every month. Then, the monthly pre-trained model is fine-tuned everyday based on the latest data. The daily fine-tuning also expands the entity id space to include the newly launching titles. After the daily fine-tuned model is ready, we run batch inference to refresh the profile and item embeddings and publish them to the Embedding Store.
An important part of this setup is the embedding stabilization technique (paper). When the pretraining job retrains the model from scratch, the embedding spaces between different runs are completely different due to the random initialization in the model. In addition, the embeddings start to drift when the daily job fine-tunes on the latest data, despite the daily fine-tuning job warm-starting from the previous day’s model. Therefore, it is important to map the embeddings generated everyday into the same embedding space, so that downstream models can consume pre-computed embeddings as features.
This embedding approach relies heavily on the Embedding Store, which is a feature store specializing in embeddings built by the platform team at Netflix. The embedding store makes producing and consuming embeddings easy by taking care of versioning and timestamping the embeddings. The Embedding Store also provides various interfaces to access the embeddings offline and online.

This approach is often the initial and most straightforward way for applications to interact with the Foundation Model. Embeddings can serve as powerful features for other models or for candidate generation, helping to retrieve appealing titles for a user or facilitate title-to-title recommendations. Integrating embeddings as features into existing pipelines is generally well-supported and offers a low barrier to entry. Compared to other integration approaches, using embeddings from the Embedding Store is expected to have a relatively smaller impact on training and inference costs.
However, this approach also has some cons. The time gap between embedding computation and downstream model inference can lead to staleness, impacting the freshness of recommendations. This may prevent applications from fully unlocking the benefit of the Foundation Model, especially for use cases requiring real-time adaptability.
Overall, the default starting point for leveraging the Foundation Model is through its profile and item embeddings via the Embedding Store, provided that the embeddings’ freshness and stability meet application-specific needs. While embeddings may not leverage the full power of the Foundation Model, they offer a good initial step.
Our biggest learning from working on this approach is that embeddings are a low cost and high leverage way of using the Foundation Model. A resilient embedding generation framework and embedding store are essential for updating the embeddings daily and serving them to application models. We found this infrastructure to be so valuable that we stepped up our investment here to build a near-realtime embedding generation framework. This new framework also enables us to update the embeddings based on user actions during the session, making the embeddings and our downstream models more adaptive. Although the near-real time framework cannot be used for very large models, it represents an important direction for addressing embedding staleness and adaptiveness of recommendations.
Foundation Model as a Subgraph
This approach involves using the Foundation Model as an input to the downstream model i.e. the Foundation Model decoder stack is a subgraph of the application model’s full model graph and hence the name “subgraph integration”. The Foundation Model subgraph processes raw user interaction sequences and outputs representations that are then fed into the downstream model graph.

Applications can fine-tune the Foundation Model subgraph as part of their own training process, potentially leading to better performance than just using static embeddings. In this approach, there is no time gap or staleness between the Foundation Model inference and the application model’s inference, ensuring that the most up-to-date learnings are used. This approach also allows applications to leverage specific layers from the Foundation Model that may not be exposed through the Embedding Store, uncovering more application-specific value.
However, the subgraph approach comes with some complexities and trade-offs. To use the Foundation Model as a subgraph, application models need to generate all the features necessary for the subgraph as part of their feature generation process. This can add time, compute and complexity to their feature gen jobs. Merging the Foundation Model as a subgraph also increases the application model size and inference time. To alleviate some of these complexities, the Foundation Model team provides some reusable code and jobs that make the feature generation more compute efficient. To optimize the inference performance, we split the subgraph and ensure it only runs once per profile per request and is shared by all items in the request.
Overall, the subgraph approach allows for a deeper integration and enables the applications to harness the full power of the Foundation Model. But it can also make the application’s training code more complex, requiring a trade-off between metric improvement, compute cost, and time. Therefore, we would reserve this approach for high impact use cases where the increase in metric wins compensate for the cost and complexity.
Fine-tuning Foundation Model and use directly
This approach is similar to fine-tuning LLMs with domain specific data. In the previous blog post, we described how the Foundation Model is trained on a next-token prediction objective, with the tokens being different user interactions. Different interactions are of different importance to various surfaces on the Netflix website. For example, for the ‘Trending now’ row, recent interactions on trending titles might be more important than old interactions. Hence, the Foundation Model can be fine-tuned on more product specific data and then the fine-tuned model can be used to directly power the product. During fine-tuning, application teams can choose to do full parameter fine-tuning or freeze some layers. They can also choose to add a different output head with a different objective. We built a fine-tuning framework to make it easy for application teams to develop their own custom fine-tuned versions of the Foundation Model.
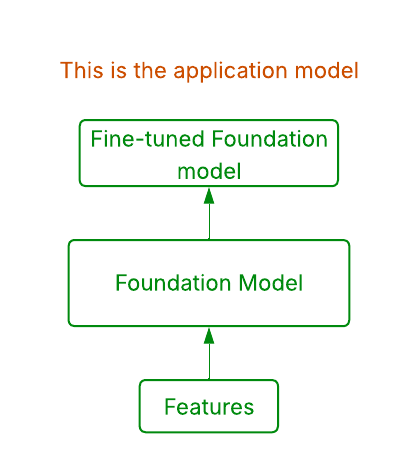
This approach offers the ability to adapt the Foundation Model to application’s specific data and objectives, making it optimized for their use case. A side benefit of this integration approach is that it provides a de facto baseline for new models/applications. Instead of coming up with a new model stack and spending months on feature engineering, new applications can directly utilize fine-tuned foundation models. However, this approach can lead to more models and pipelines to maintain across the organization.The latency and Service Level Agreements (SLAs) of the fine-tuned model must be carefully optimized for the specific application use case.
Conclusion
We are continuing to innovate on these integration approaches over time. For example, the Machine Learning Platform team is working on near-real time embedding inference capabilities to address the staleness issues with the embedding approach. We are also working on a smaller distilled version of the Foundation Model to reduce the inference latency of the subgraph approach. We also provide a fine-tuning framework to make it easy to fine-tune and leverage the Foundation Model. We also continue to refine and standardize the APIs used in these approaches to make it easy for application teams to use them. Overall, these three integration patterns provide a comprehensive framework for how Netflix applications can interact with and extract value from the Foundation Model.
Acknowledgements
We thank our stunning colleagues in the Foundation Model team for developing and continuing to innovate on the Foundation Model. We thank our colleagues in the AIMS applications teams for driving the integrations and their valuable feedback and discussions. We also thank our Machine Learning Platform team for building and supporting the infra components to get these approaches up and running in production.
Contributors to this work (name in alphabetical order): Davis Shepherd Inbar Naor Jin Wang Jonathan Indig Kevin Zielnicki Luke Wang Mario Garcia-Armas Maryam Esmaeli Michael Tu Nicholas Hortiguera Qiuling Xu Robbie Greuner Roger Menezes Sejoon Oh Trung Nguyen Vito Ostuni Yesu Feng.