After text and images, is video how AI truly learns to think dynamically?
Thinking with Video: Video Generation as a Promising Multimodal Reasoning Paradigm...
We’ve spent years teaching AI to reason better. First came chain-of-thought prompting, which let language models talk through their logic step-by-step instead of jumping straight to answers. Then came vision language models, which grounded reasoning in actual images. Both worked. Both improved the numbers.
But there’s a fundamental problem nobody talks about: these approaches reach a wall, and the wall is time.
Text reasoning can describe a process step-by-step, but it’s abstract. When you ask an AI to solve a geometry puzzle or verify a mechanical process, explaining it in words feels clumsy. You’re describing spatial relationships with tokens.
Images, meanwhile, are frozen moments. A single photograph of water halfway filling a glass conveys something, sure, but it’s not the same as a video of water being poured. Many real reasoning tasks are inherently temporal or spatial in ways that demand motion: drawing shapes to verify geometry, animating a mechanical process to check if it works, simulating a step-by-step transformation to find a pattern. Static frames fail to capture the essence of how one state becomes another.
And then there’s the deeper architectural problem: text and vision stay in separate lanes. Current systems either think with text about images, or think with images about text. They’re dual systems pretending to be unified. There’s no natural way for visual reasoning to flow into textual reasoning or vice versa.
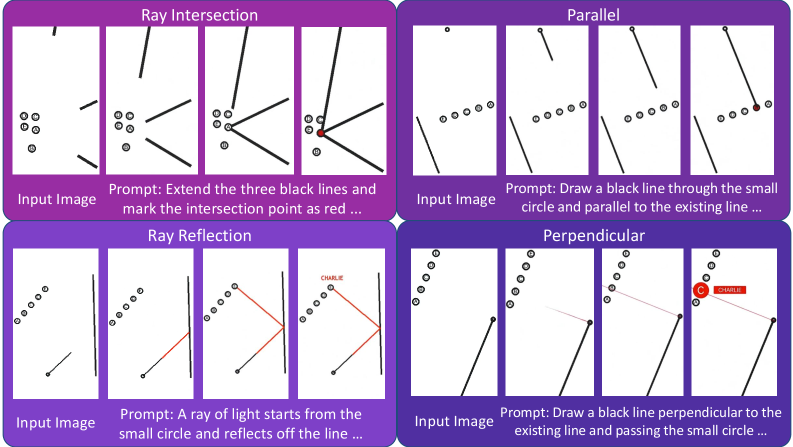
This paper asks a simple but radical question: what if we let AI models generate videos to think through problems? Not to communicate answers, but to actually reason. Let the model externalize its thinking process into motion. The answer reveals something surprising: video might not just be a richer format, it might be the key to unified multimodal reasoning.
What video thinking actually means
Before diving into results, the mechanism itself needs clarification. What does it actually mean to “reason by generating video”?
Think of it as giving an AI a way to externalize its internal reasoning process. Instead of computing an answer silently and outputting text, the model “thinks out loud” by generating a sequence of images. The video is the reasoning. When you ask it to solve a puzzle, it animates the solution step-by-step. When you ask it to find a pattern, it generates frames that show the transformation unfolding.
The key insight is that modern video generation models like Sora-2 are trained to generate plausible sequences of images that follow physical and logical rules. This constraint on coherence between frames, “what you generate in frame N should lead sensibly to frame N+1,” is actually a strong signal for reasoning. It’s a built-in consistency check that text reasoning doesn’t have.